AskSauron
Overview
AskSauron is a high-performance distributed search engine built in Java to support the full search lifecycle, from crawling and indexing to ranking and retrieval.
The system is powered by a custom Key-Value Store and Flame, a distributed processing framework built from scratch in Java and modeled after Apache Spark, designed to execute parallel dataflow jobs across the pipeline. The pipeline processed over 1 million crawled pages and produced an indexed corpus of about 520,000 validated documents.
Although the software architecture is fully distributed, deployment was optimized on a high-performance AWS EC2 environment running multiple concurrent worker processes across the crawl, indexing, and ranking stages.
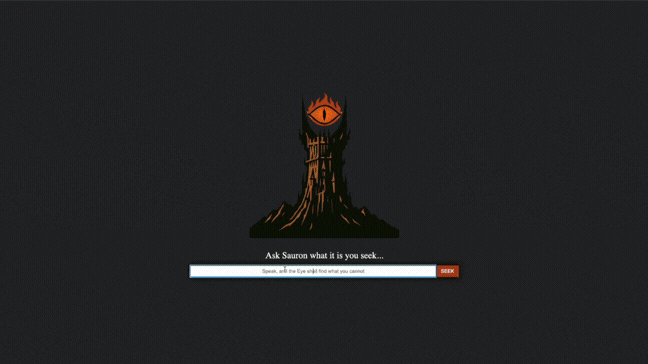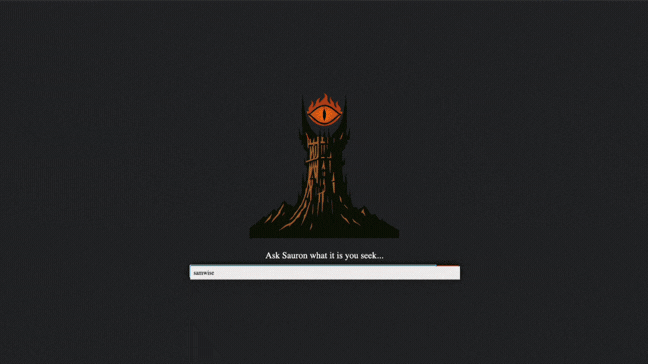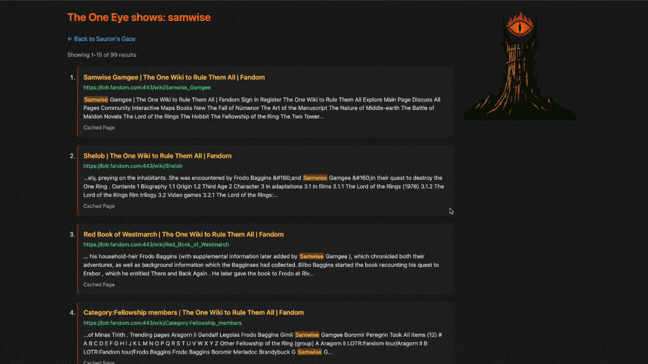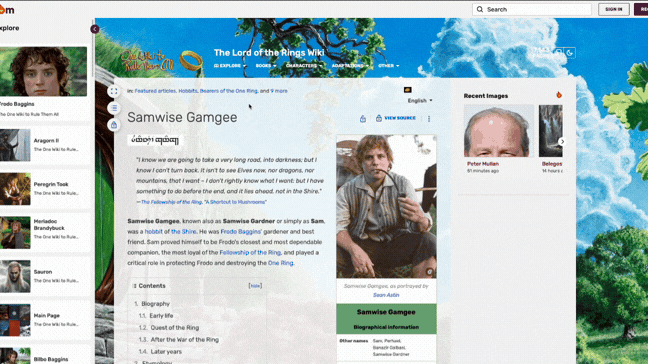
Results & Core Features
- Data Pipeline Scale: Processed over 1,000,000 raw pages, filtered down to a high-quality index of ~520,000 unique validated documents.
- High-Performance Frontend UX: Includes real-time search suggestions (binary search), spellcheck (Levenshtein distance), and a capped in-memory query cache to quickly serve repeated searches.
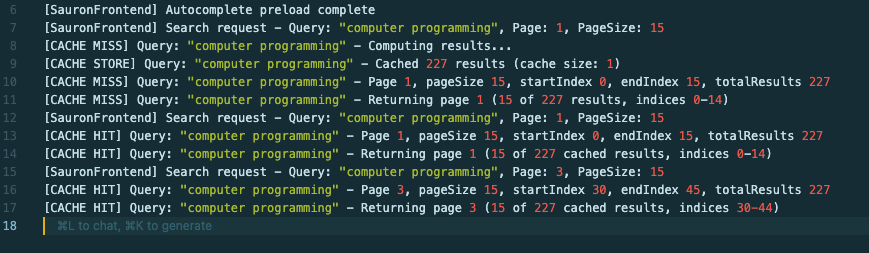
- Cached Page Access: Served stored snapshots of indexed pages so content remained viewable even if the original source was down or had changed.
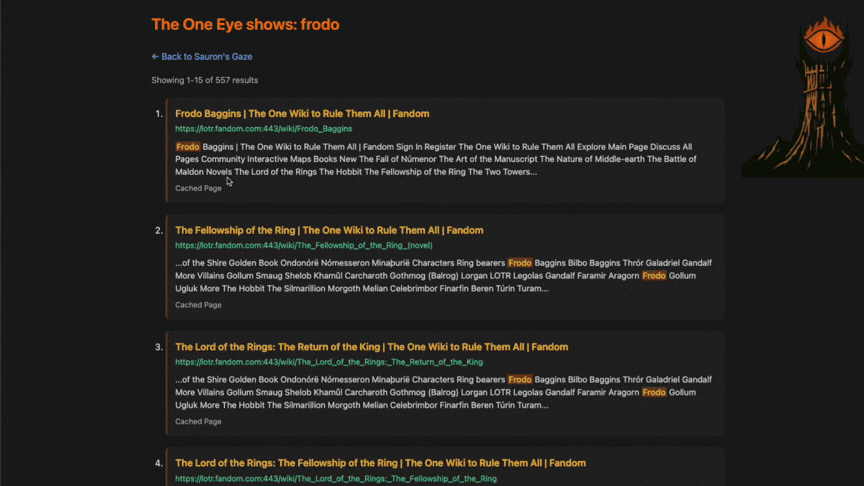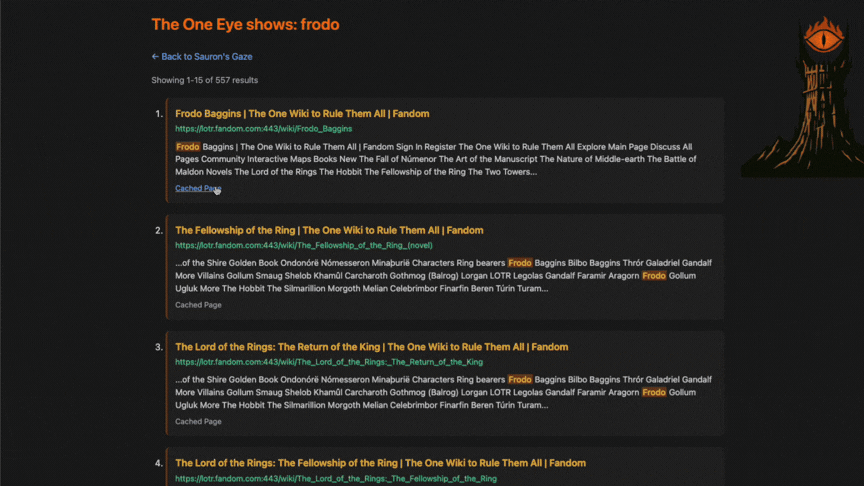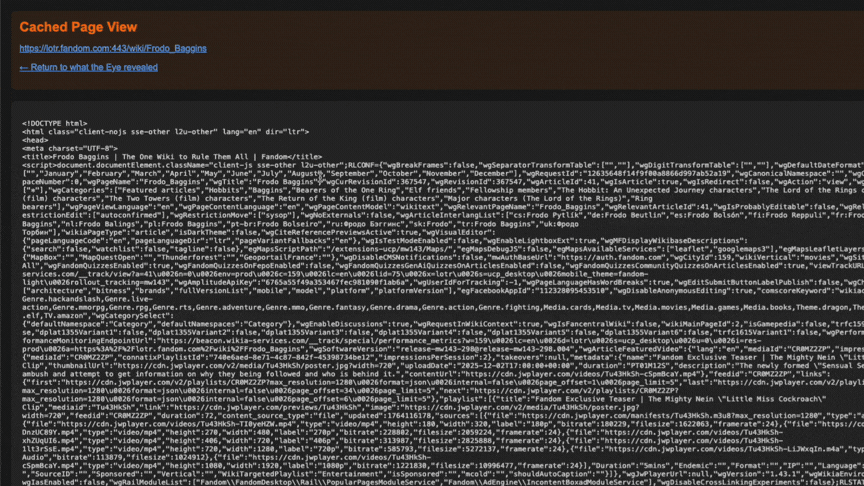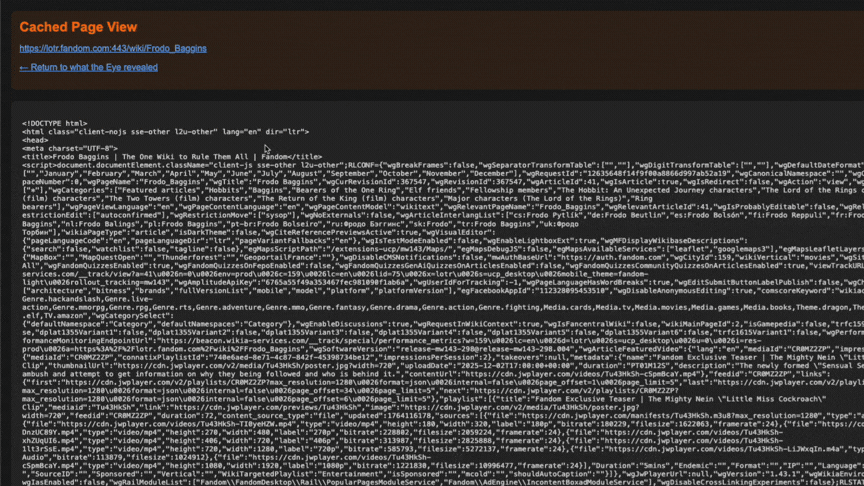
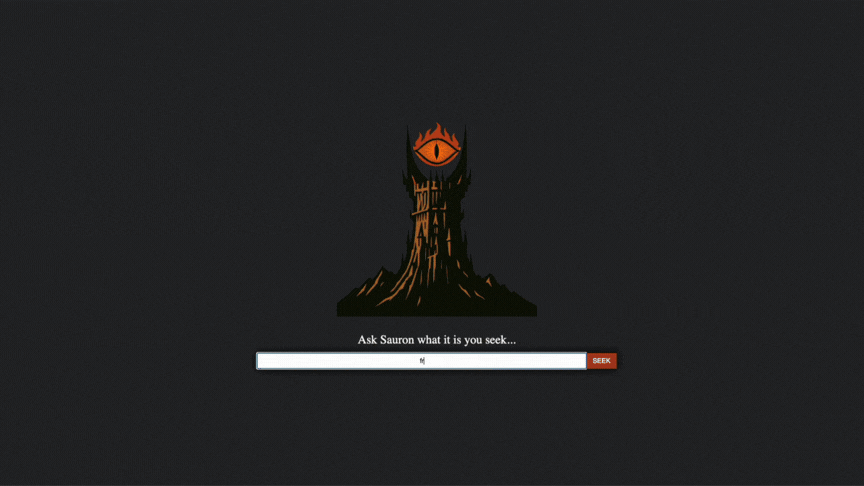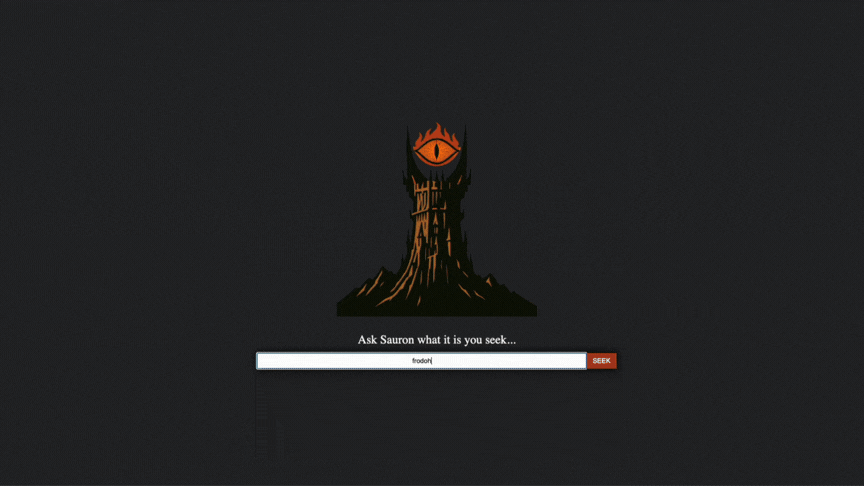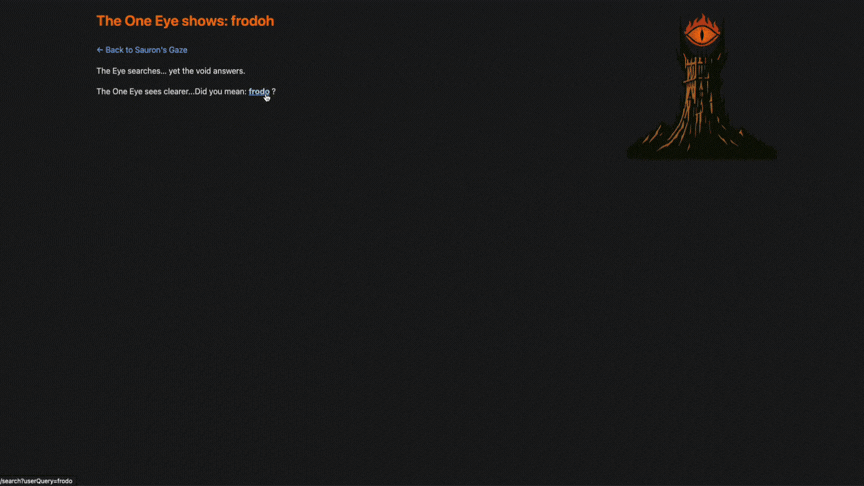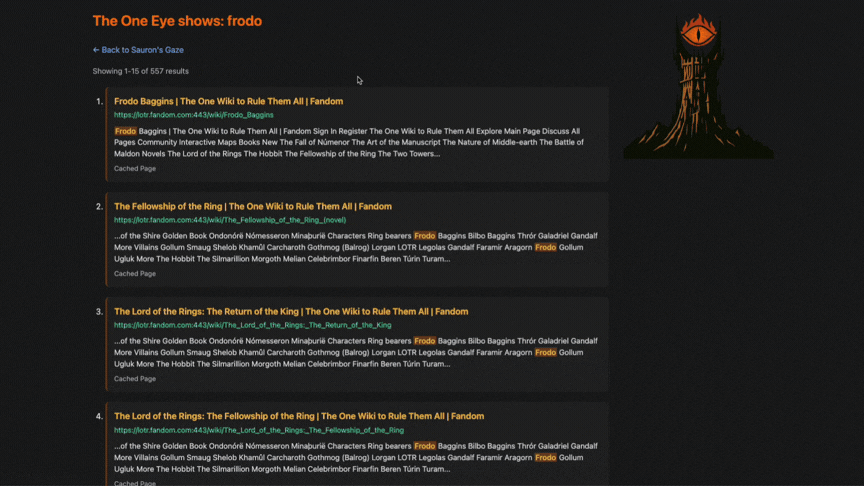
- Search Result Preview Snippets: Built dynamic 350-character contextual previews from page content, with matched query terms highlighted for readability.
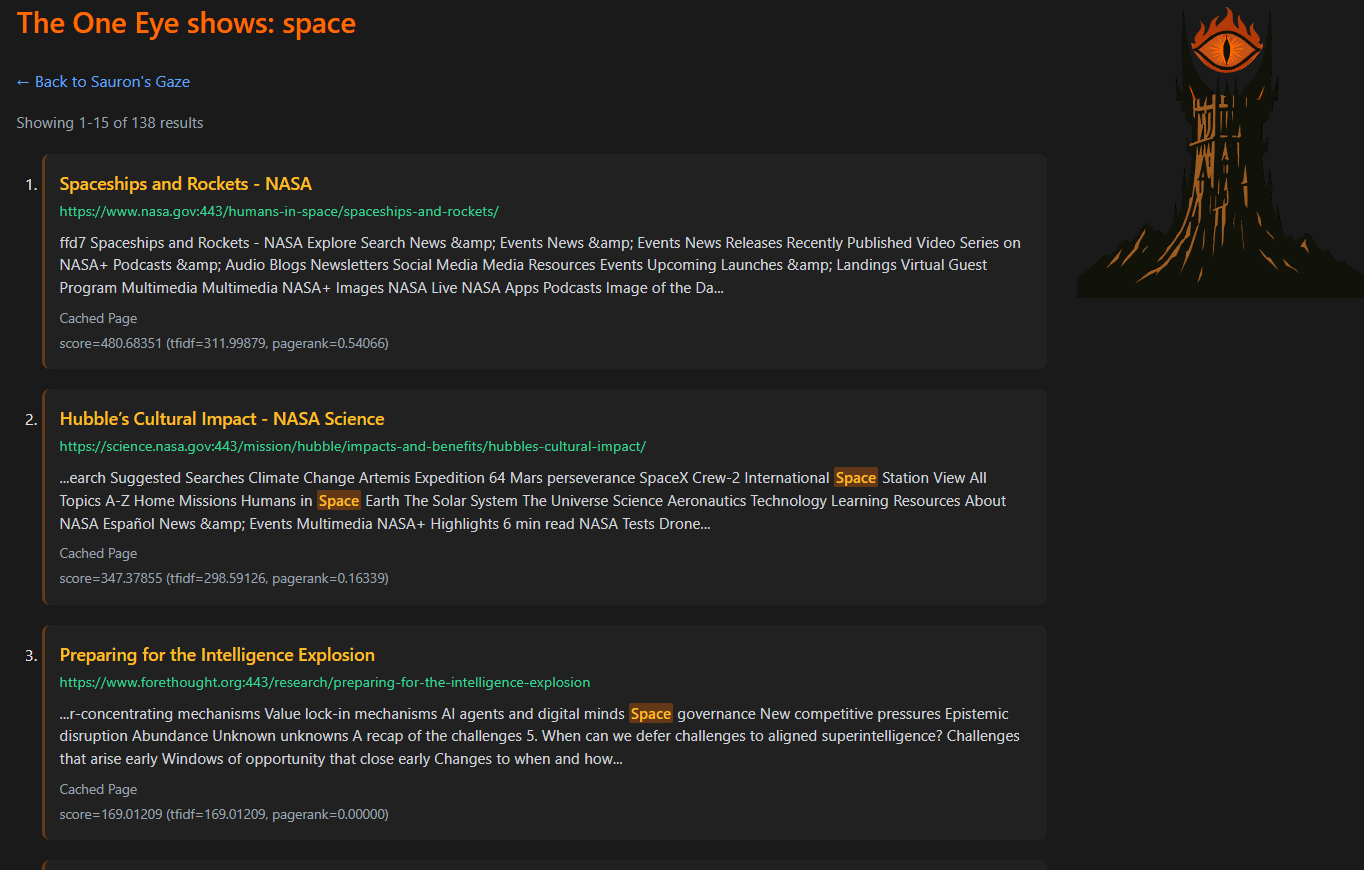
- Linguistic Normalization: Integrated the OpenNLP PorterStemmer library to stem words (e.g., “computing” to “compute”) at both index and query time, drastically improving search recall.
- Resilient Infrastructure: Engineered checkpoint-based start/resume functionality across the Crawler, Indexer, and PageRank pipeline jobs to automatically recover from worker timeouts or Out-of-Memory (OOM) crashes.
System Architecture & Data Flow
The system operates through a coordinator-worker model using Flame, our Spark-like distributed processing engine. Flame provides RDD-style functional operators (map, flatMapToPair, foldByKey, join) that allow us to write large-scale jobs as parallel dataflow pipelines.
- Distributed Crawler: Discovers and archives raw HTML into a persistent KVS table, filtering out infinite content traps as it extracts new URLs.
- Inverted Indexer: A multi-threaded Flame job that strips boilerplate tags, tokenizes text, and maps term positions to compute Term Frequencies.
- Offline Ranking Engine: Computes global authority via iterative PageRank jobs and outputs
pt-pageranksfor online lookup. - Search Retrieval Frontend: A low-latency service that computes score online using
pt-index+pt-pageranks, applies dynamic boosts, reads titles frompt-documentStats, and lazily extracts 350-character contextual previews from cached HTML.

Ranking Engine: TF-IDF & PageRank
TF-IDF (Relevance)
Term Frequency-Inverse Document Frequency measures how relevant a page is to your search.
- TF: How many times your word appears on a specific page.
- IDF: How “rare” that word is across our ~520,000 pages. Common words like “the” are penalized, while unique words receive a boost.
- Weights: We give visible text a weight of 1.0 but penalize hidden metadata at 0.001 to prevent “keyword stuffing.”
Iterative PageRank (Authority)
PageRank measures “trust” by treating links as votes. We compute this on hashed URLs using an iterative loop. Each page state tracks currentRank, previousRank, and outlinks.
- Transfer Step: A page takes 85% of its rank and divides it equally among its outlinks. A link from a page with few outlinks provides a “stronger” vote than one with thousands.
- Aggregation: Pages sum all incoming contributions and add a 0.15 baseline to find their
newRank. - Convergence: The job continues until 95% of pages are “stable”—meaning their score changed by less than 0.01 since the last loop. This specific threshold ensures accuracy without wasting compute time or crashing the server due to OOM.
Final Scoring: Typing vs. Searching
Our system distinguishes between quick suggestions and full search results:
-
The Suggestions (
/suggest): When you type, the engine uses a fast binary search on a sorted dictionary to finish your words. No complex scoring happens here. -
The Full Search (
/search): Once you hit enter, the engine runs the full retrieval pipeline:- Batch KVS Read:
pt-index+pt-pageranks+pt-documentStats - Core Combine:
(base_tfidf * phrase_boost) * (1.0 + pagerank) - Heuristic Multipliers:
- Multi-term coverage: Documents matching all query terms get a 4.0x boost.
- Title Alignment: Matches in the page
<title>receive up to a 4.0x boost. - URL Matching: Terms found in the URL path grant up to a 5.0x boost.
- Batch KVS Read:
Final Score = Core Combine * Coverage Boost * Title Boost * URL Boost
Engineering Challenges
Making Search Results Reliable on Messy Web Data
A major challenge was that real web pages are noisy. Many pages contained broken HTML, repeated boilerplate, metadata-heavy scripts, and SEO-stuffed keyword blocks that made irrelevant pages look more important than they were. In some cases, a document ranked highly even though the query terms barely appeared in the visible page content; they were buried in <meta> tags or keyword fields.
To improve relevance, we changed the indexing pipeline to separate visible text from metadata. Visible page text was weighted normally at 1.0, while metadata keywords were given only a tiny contribution at 0.001, so hidden SEO tricks could not overpower the actual page content. We also excluded stopwords from TF-IDF scoring while preserving them for phrase search, which helped prevent common words from distorting rankings.
This was also a performance problem. Malformed HTML and regex-heavy cleaning slowed the indexer at scale, so we moved toward faster character-level tokenization and reduced unnecessary intermediate key-value pairs. These changes made the indexer both more accurate and more scalable across hundreds of thousands of pages.
Keeping Distributed Jobs Stable at Scale
Long-running crawl, index, and PageRank jobs exposed a different kind of challenge: reliability. The system had to handle oversized pages, unstable network responses, unexpected content types, worker timeouts, and large intermediate data structures. Early versions could stall, crash, or slow down significantly under load.
We improved stability through defensive parsing, stricter validation, retry logic, and system-level tuning. Adjusting worker counts, coordinator concurrency, thread pools, and hash bucket sizes helped us find a better balance between parallelism and overhead. We also added bucket-based checkpoints so the crawler, indexer, and PageRank jobs could resume from the last completed bucket instead of restarting the entire 1-million-page pipeline.
Validating the Pipeline Through Internal Tooling
One of the trickiest debugging moments came from our internal KVS UI, which we used to inspect worker tables and verify that the crawl/index pipeline was producing the expected data. During testing, the UI reported about 5x more pagination pages than the actual number of indexed rows, which initially suggested that the indexer might be emitting empty rows, duplicate output, or incorrect intermediate data.
We traced the issue across worker tables, intermediate outputs, and coordinator logic, then validated the indexed rows directly. This confirmed that the production pipeline was correct: the inflated count came from the debugging UI’s pagination logic, which counted empty worker partitions as pages even though they did not represent actual indexed documents.
By separating a true pipeline defect from an internal observability issue, we avoided spending more time on non-critical tooling and stayed focused on the search path that mattered most: crawling, indexing, ranking, and retrieval.